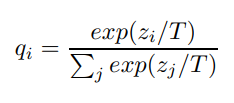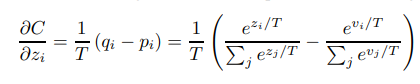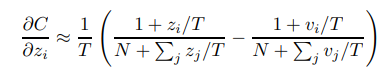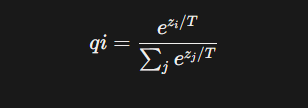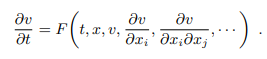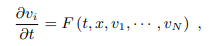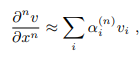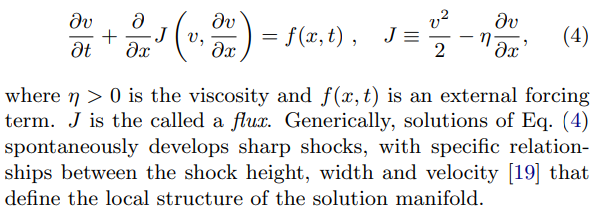머신러닝 디자인패턴을 읽던 중 4장 distilling 에 관한 기법이 나와 찾아보게 되었습니다.
요약
지금까지으 대규모 머신러닝 시스템은 학습과 배포단계에서 같으느 모델을 사용했는데 이때문에 추론 레벨에서 리소스가 커진다는 단점이 있었습니다. 그래서 거대한 모델로부터 지식을 하나의 작은 모델로 전이하는 방법을 통해 이 제약을 극복하려고 합니다. 이것이 “증류” 의 표현입니다.
기존의 hard label 은 [1,0,0] 처럼 정확한 확률을 알려주었는데, 실제로는 고양이를 닮은 개가 있을수도 있으니 [0.6,0.4,0] 같은 label 도 의미있는 지식일 수 있다는것이 아이디어 입니다.
그래서 정리하자면 거대한 모델에서 산출된 마지막 레이어의 값들을 학습에 활용하는 soft target 으로 활용하자는 것입니다.
Distillation
기존의 신경망은 클래스 분류 태스크를 수행할 때 output layer 에 softmax 를 취해 logit 을 변환합니다.
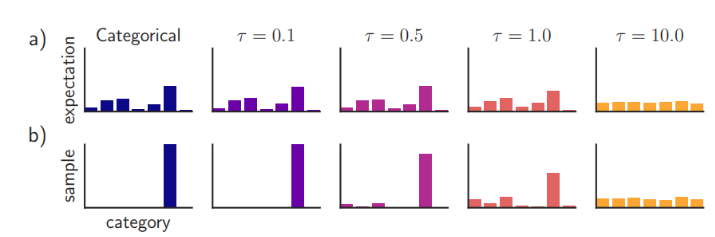
일반적으로 T 는 1로 세팅되어 있습니다. T를 높게 할수록 클래스 확률값이 soft 하게 출력됩니다.
T 가 커질수록 클래스 값들이 soft 해지는 것을 알 수 있습니다.
논문에서 제안한 “증류” 의 방식은 거대한 모델을 teacher model 로 특수한 목적으로 만들 작은 모델을 Student(distilled model) 이라 합니다.
t를 최대로 하고, 기존의 transfer dataset 을 teacher 모델에 넣고 soft label (1) 을 얻습니다. 그리고 student 모델에 inference 해서 soft prediction(2) 을 얻습니다. 그리고 student model 에서 hard prediction(3)결과를 얻습니다. 그리고 (1) 와 (2) 의 cross entropy , (2) 와 (3) 의 cross entropy 를 가중합 하는 방식이 성능이 좋다고 합니다.
cross entropy gradient 의 는 아래와 같이 나타냅니다. 여기서 Vi 는 큰 모델의 결과값을 나타내고 pi 는 soft label 의 확률값을 의미합니다. 그러니까 qi 와 pi 의 cross entropy 를 계산하는 문제가 logit 간의 차이를 근사하는 문제로 변환시키고 있음을 의미합니다.
증류에서 Teacher Model 과 Student 의 모델 output 차이를 활용해 gradient 계산을 하려는 움직임입니다.
여기서 T가 충분히 크다면 테일러 근사를 활용해 아래와 같이 나타낼 수 있습니다
그리고 logit 의 평균이 0 이라고 가정한다면 0 으로 변환되니
student model output 에 대한 Cross entropy 변화율 즉 gradient 는 nt^1 에 반비례하게 됩니다. 그래서 결론은 “T가 충분히 큰 상황에서 logit 들의 평균이 0 으로 주어졌다면, Distillation 은 1/nt^2 을 최소화 하는 문제가 됩니다.
반대로 T 가 낮다면 gradient 를 최대화 시키니 모델이 너무 작다면 중간정도의 temperature 를 사용하는것이 좋다고 주장합니다
기여도
본 논문의 가장 큰 기여는 다음 세 가지로 정리할 수 있습니다.
1. Soft Target을 활용한 지식 전달 방식의 정식화
기존의 분류 모델은 정답 레이블(one-hot 벡터)만을 학습 신호로 사용하였습니다. 그러나 본 논문은 모델의 출력 확률 분포 전체가 지식이라는 관점을 제시하였습니다.
특히 Teacher 모델이 출력한 softmax 확률 분포에는 다음과 같은 정보가 포함되어 있습니다.
클래스 간 유사도
모델이 헷갈리는 정도
데이터 분포에 대한 암묵적 구조
이를 Student 모델이 학습하도록 만들면, 단순히 정답을 맞추는 것이 아니라 Teacher의 판단 구조 자체를 모방하게 됩니다.
이는 이후 모든 Knowledge Distillation 연구의 출발점이 되었습니다.
2. Temperature 기반 확률 분포 제어 메커니즘 제안
논문은 softmax 함수에 temperature TTT를 도입하여 확률 분포를 조절하는 방식을 제안하였습니다.
T=1일 경우 일반적인 softmax
T>1일 경우 분포가 평탄해짐
Temperature를 높이면 모델의 확신(confidence)이 낮아지고, 클래스 간 상대적 관계 정보가 더 잘 드러납니다. 이로 인해 Student 모델은 단순 정답이 아니라 확률 구조 자체를 학습하게 됩니다.
이러한 수학적 근사 분석을 통해, KD가 결국 logit 간 차이를 줄이는 문제로 수렴한다는 것을 보인 점 역시 중요한 기여입니다.
3. 앙상블 모델의 압축 방법 제시
논문은 여러 개의 모델을 앙상블하여 얻은 고성능 Teacher 모델을 단일 Student 모델로 압축할 수 있음을 보였습니다.
이는 다음과 같은 실용적 의미를 가집니다.
학습 단계에서는 대규모 모델 사용
배포 단계에서는 경량 모델 사용
추론 속도 향상 및 리소스 절감
즉, 학습과 배포의 구조적 분리를 가능하게 한 기법이라는 점에서 산업적 의미가 매우 큽니다.
실험결과
MNIST
MNIST 실험에서는 다음과 같은 설정을 사용하였습니다.
Teacher 모델: 여러 개의 모델을 앙상블한 고성능 네트워크
Student 모델: 상대적으로 작은 네트워크
결과적으로 Student 모델은 다음과 같은 특징을 보였습니다.
일반적인 hard label 학습 대비 더 낮은 error rate
Teacher의 성능에 근접한 정확도 달성
과적합 감소 효과
특히 데이터가 충분하지 않은 상황에서도 soft target을 사용하면 일반화 성능이 개선되는 경향을 보였습니다.
이는 soft target이 일종의 regularizer 역할을 수행한다는 것을 의미합니다.
Speech Recognition
음성 인식 실험에서는 대규모 acoustic model을 Teacher로 사용하였습니다.
Teacher는 매우 복잡하고 큰 네트워크였으며, 직접 배포하기에는 비효율적이었습니다.
Distillation을 적용한 Student 모델은:
파라미터 수 감소
추론 속도 개선
정확도는 Teacher에 근접
특히 soft target 기반 학습이 hard label 기반 학습보다 안정적인 수렴 특성을 보였습니다.
이는 KD가 classification뿐 아니라 sequence 기반 문제에도 적용 가능함을 보여주는 사례입니다.
vllm 서버 운영중 0.14.0 미만 버전에서 RCE 취약점이 발생했다고 해서 버전 패치를 했습니다.
그런데 이전에 나와있던 취약점 중 모델 로드를 통해서 RCE 가 발생할 수 있다는 글을 보
고 이게 어떻게 가능한건지 찾아보게 되었는데요,
배포포맷이나 일부 프레임워크에서 모델로드에서 가중치만 불러오는것이 아니라
파이썬 코드 로직을 탈 수 있다는 사실을 알게 되어 정리할 겸 글을 작성합니다.
인공지능 모델을 개발하다 보면 학습 자체보다 더 많은 문제가 발생하는 지점이 바로 배포입니다. 학습된 모델은 단순한 코드가 아니라 수백 MB에서 수십 GB에 이르는 가중치 데이터와 실행 구조를 함께 갖고 있기 때문입니다. 이때 모델을 어떤 형태로 저장하고 전달할 것인가에 대한 문제가 바로 모델 배포 포맷의 출발점입니다.
초기에는 학습한 프레임워크 내부에서만 모델을 사용했기 때문에, 단순히 메모리 객체를 그대로 직렬화하는 방식이 사용되었습니다. 하지만 모델이 커지고, 협업과 외부 공유가 늘어나면서 자연스러운 요구사항이 등장했습니다. 가장 큰 것은 다른 환경에서도 동일하게 모델을 로드할 수 있어야 한다는 것인데요, 모델을 만들고 학습시키는 것은 전체 파이프라인을 구성하지 않는 한 그다지 문제가 되지 않습니다만, 추론을 할 때에는 이식성이 중요하게 여겨졌습니다. 그래서 모델 파일만 export 하게 되었고, 이런 요구사항들을 해결하기 위해서 여러가지 모델 배포 포맷이 등장하게 되었습니다.
Pytorch .pt.pth
Pytorch 의 모델 저장 방식은 Python 객체를 그대로 데이터로 만드는 것인데 이것을 직렬화라고 합니다. 이 포맷도 다른 포맷들과 마찬가지로 모델 재현성의 요구사항을 해결했기 때문에 Research Level 에서는 편하게 사용될 수 있지만, 내부적으로 pickle 을 사용하고, 코드나 데이터 자체를 모두 직렬화 하기 때문에 해당 객체를 로드하는 경우 RCE가 가능하다는 치명적인 문제가 있습니다.
python 공시문서에서 pickle 은 직렬화와 역직렬화를 위한 모듈이라고 나와있습니다. 다른 예시로 사용되는 것들도 나중에 한번 찾아볼법 한 것 같습니다.
# Define model
class TheModelClass(nn.Module):
def __init__(self):
super(TheModelClass, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# Initialize model
model = TheModelClass()
만약 위와 같은 모델이 있다면 torch.save 하는 시점에서 TheModelClass 가 직렬화됩니다. 그럼 class 안에 있는 함수들에 뭔가 다른 목적의 코드가 있다면 torch.load() 하는 시점에서 그대로 실행되겠지요. 이것이 pytorch 의 model.state_dict() 를 저장하지 않고 save 했을 때의 문제점 입니다. 그래서 pytorch 권장사항은 파라미터만 저장되게 하는 torch.save(model.state_dict,’model.pth’) 메서드를 사용하게 합니다.
Huggingface .safetensors
safetensors 는 가중치를 빠르게 저장하고 불러오기 위한 형식인데요, 다른 모델에서 발생할 수 있는 취약점 문제 특히 pickle 을 사용하면서 발생하는 python 객체저장이나 실행가능한 구조를 포함하고 있지 않습니다. safetensors 파일 구조는 헤더와 블록으로 구성되어 있습니다.
헤더는 JSON 형식으로 된 텐서들의 메타데이터이고, 데이터블록은 weight들이 존재하는 바이너리 형태입니다. 실제로 safetensors 를 열어서 확인해볼 수 있는데요
의 두번째 safetensors 가 발견한것중 용량이 좀 작네요, 이거로 테스트 해보셔도 좋을 듯 합니다.
from safetensors import safe_open
safetensors_file =
with safe_open(safetensors_file, framework="pt") as f:
tensor_name = f.keys()
print(f"tensor list {tensor_name}")
for key in tensor_name:
tensor = f.get_tensor(key)
print(f"tensor name {key} 의 데이터타입 : {tensor.dtype}")
print(f"tensor name {key} 의 shape : {tensor.shape}")
tensor list ['thinker.model.layers.5.mlp.gate_proj.weight', 'thinker.model.layers.5.mlp.up_proj.weight', 'thinker.model.layers.5.post_attention_layernorm.weight', 'thinker.model.layers.5.self_attn.k_norm.weight', 'thinker.model.layers.5.self_attn.k_proj.weight', 'thinker.model.layers.5.self_attn.o_proj.weight', 'thinker.model.layers.5.self_attn.q_norm.weight', 'thinker.model.layers.5.self_attn.q_proj.weight', 'thinker.model.layers.5.self_attn.v_proj.weight', 'thinker.model.layers.6.input_layernorm.weight', 'thinker.model.layers.6.mlp.down_proj.weight', 'thinker.model.layers.6.mlp.gate_proj.weight', 'thinker.model.layers.6.mlp.up_proj.weight', 'thinker.model.layers.6.post_attention_layernorm.weight', 'thinker.model.layers.6.self_attn.k_norm.weight', 'thinker.model.layers.6.self_attn.k_proj.weight', 'thinker.model.layers.6.self_attn.o_proj.weight', 'thinker.model.layers.6.self_attn.q_norm.weight', 'thinker.model.layers.6.self_attn.q_proj.weight', 'thinker.model.layers.6.self_attn.v_proj.weight', 'thinker.model.layers.7.input_layernorm.weight', 'thinker.model.layers.7.mlp.down_proj.weight', 'thinker.model.layers.7.mlp.gate_proj.weight', 'thinker.model.layers.7.mlp.up_proj.weight', 'thinker.model.layers.7.post_attention_layernorm.weight', 'thinker.model.layers.7.self_attn.k_norm.weight', 'thinker.model.layers.7.self_attn.k_proj.weight', 'thinker.model.layers.7.self_attn.o_proj.weight', 'thinker.model.layers.7.self_attn.q_norm.weight', 'thinker.model.layers.7.self_attn.q_proj.weight', 'thinker.model.layers.7.self_attn.v_proj.weight', 'thinker.model.layers.8.input_layernorm.weight', 'thinker.model.layers.8.mlp.down_proj.weight', 'thinker.model.layers.8.mlp.gate_proj.weight', 'thinker.model.layers.8.mlp.up_proj.weight', 'thinker.model.layers.8.post_attention_layernorm.weight', 'thinker.model.layers.8.self_attn.k_norm.weight', 'thinker.model.layers.8.self_attn.k_proj.weight', 'thinker.model.layers.8.self_attn.o_proj.weight', 'thinker.model.layers.8.self_attn.q_norm.weight', 'thinker.model.layers.8.self_attn.q_proj.weight', 'thinker.model.layers.8.self_attn.v_proj.weight', 'thinker.model.layers.9.input_layernorm.weight', 'thinker.model.layers.9.mlp.down_proj.weight', 'thinker.model.layers.9.mlp.gate_proj.weight', 'thinker.model.layers.9.mlp.up_proj.weight', 'thinker.model.layers.9.post_attention_layernorm.weight', 'thinker.model.layers.9.self_attn.k_norm.weight', 'thinker.model.layers.9.self_attn.k_proj.weight', 'thinker.model.layers.9.self_attn.o_proj.weight', 'thinker.model.layers.9.self_attn.q_norm.weight', 'thinker.model.layers.9.self_attn.q_proj.weight', 'thinker.model.layers.9.self_attn.v_proj.weight', 'thinker.model.norm.weight']
tensor name thinker.model.layers.5.mlp.gate_proj.weight 의 데이터타입 : torch.bfloat16
tensor name thinker.model.layers.5.mlp.gate_proj.weight 의 shape : torch.Size([6144, 2048])
tensor name thinker.model.layers.5.mlp.up_proj.weight 의 데이터타입 : torch.bfloat16
tensor name thinker.model.layers.5.mlp.up_proj.weight 의 shape : torch.Size([6144, 2048])
tensor name thinker.model.layers.5.post_attention_layernorm.weight 의 데이터타입 : torch.bfloat16
tensor name thinker.model.layers.5.post_attention_layernorm.weight 의 shape : torch.Size([2048])
tensor name thinker.model.layers.5.self_attn.k_norm.weight 의 데이터타입 : torch.bfloat16
tensor name thinker.model.layers.5.self_attn.k_norm.weight 의 shape : torch.Size([128])
tensor name thinker.model.layers.5.self_attn.k_proj.weight 의 데이터타입 : torch.bfloat16
tensor name thinker.model.layers.5.self_attn.k_proj.weight 의 shape : torch.Size([1024, 2048])
tensor name thinker.model.layers.5.self_attn.o_proj.weight 의 데이터타입 : torch.bfloat16
tensor name thinker.model.layers.5.self_attn.o_proj.weight 의 shape : torch.Size([2048, 2048])
tensor name thinker.model.layers.5.self_attn.q_norm.weight 의 데이터타입 : torch.bfloat16
tensor name thinker.model.layers.5.self_attn.q_norm.weight 의 shape : torch.Size([128])
tensor name thinker.model.layers.5.self_attn.q_proj.weight 의 데이터타입 : torch.bfloat16
tensor name thinker.model.layers.5.self_attn.q_proj.weight 의 shape : torch.Size([2048, 2048])
tensor name thinker.model.layers.5.self_attn.v_proj.weight 의 데이터타입 : torch.bfloat16
tensor name thinker.model.layers.5.self_attn.v_proj.weight 의 shape : torch.Size([1024, 2048])
tensor name thinker.model.layers.6.input_layernorm.weight 의 데이터타입 : torch.bfloat16
tensor name thinker.model.layers.6.input_layernorm.weight 의 shape : torch.Size([2048])
tensor name thinker.model.layers.6.mlp.down_proj.weight 의 데이터타입 : torch.bfloat16
tensor name thinker.model.layers.6.mlp.down_proj.weight 의 shape : torch.Size([2048, 6144])
tensor name thinker.model.layers.6.mlp.gate_proj.weight 의 데이터타입 : torch.bfloat16
tensor name thinker.model.layers.6.mlp.gate_proj.weight 의 shape : torch.Size([6144, 2048])
tensor name thinker.model.layers.6.mlp.up_proj.weight 의 데이터타입 : torch.bfloat16
tensor name thinker.model.layers.6.mlp.up_proj.weight 의 shape : torch.Size([6144, 2048])
tensor name thinker.model.layers.6.post_attention_layernorm.weight 의 데이터타입 : torch.bfloat16
weight 에 대한 데이터가 있는것을 볼 수 있습니다. RCE 를 원천적으로 막기 위해 설계 된 만큼 safetensors 모델자체에 대해서는 발견된 취약점이 없습니다.
Microsoft ONNX(Open Neural Network Exchange)
ONNX 는 많은 머신러닝 프레임워크 간의 모델을 통합할 수 있도록 설계된 오픈소스 포맷입니다. ONNX 를 통해서 개발자들은 Pytorch 나 Tensorflow 등 상이한 머신러닝 프레임워크에서 개발해도 ONNX 를 통해서 서로다른 프레임워크로 쉽게 전환해서 사용할 수 있습니다. 이 역시 배포를 원활하게 하자는 정신에서 개발되었습니다.
import torch
import torchvision.models as models
import onnx
# 사전 훈련된 PyTorch 모델 로드
model = models.resnet18(pretrained=True)
model.eval()
# 더미 입력 데이터 생성
x = torch.randn(1, 3, 224, 224, requires_grad=True)
# 모델을 ONNX 포맷으로 변환
torch.onnx.export(model, # 실행할 모델
x, # 모델 입력값 (튜플 또는 여러 입력값을 위한 튜플도 가능)
"resnet18.onnx", # 저장될 모델의 이름
export_params=True, # 모델 파일 내 학습된 모델 가중치를 저장할지의 여부
opset_version=10, # 모델을 변환할 때 사용할 ONNX 버전
do_constant_folding=True, # 최적화: 상수 폴딩을 수행할지 여부
input_names = ['input'], # 모델의 입력값에 대한 이름
output_names = ['output'], # 모델의 출력값에 대한 이름
dynamic_axes={'input' : {0 : 'batch_size'}, # 배치 크기에 따라 동적으로 변하는 입력 차원
'output' : {0 : 'batch_size'}}) # 배치 크기에 따라 동적으로 변하는 출력 차원
ONNX 발생 가능한 취약점
최근까지는 ONNX 의 보고된 취약점들에서 ONNX 자체의 취약점은 거의 없다고 해도 될정도로 없었고, 게다가 RCE 는 전혀 볼수 없었습니다. 이 마저도 C/C++ 엄밀히 말하면 런타임 유형의 취약점이라고 할 수 있었다는데요, 최근 발표 된 Path Traveling 취약점도 ONNX 포맷의 문제라기보다는, ONNX 모델을 처리하는 라이브러리 구현의 취약점이라고 합니다.
GGML은 Georgi Gerganov가 개발한 경량 머신러닝 라이브러리로, 대규모 언어 모델을 포함한 신경망 모델을 CPU 환경에서 효율적으로 추론하기 위해 설계된 C/C++ 기반 프로젝트입니다. Hugging Face의 소개 글에서도 강조하듯, GGML은 기존 딥러닝 프레임워크가 갖는 복잡성과 무거운 의존성을 최소화하는 것을 목표로 만들어졌습니다.
일반적인 머신러닝 프레임워크인 PyTorch나 TensorFlow는 매우 강력하지만, 대규모 라이브러리 의존성과 복잡한 빌드 환경을 요구합니다. 이는 서버 환경에서는 문제가 되지 않을 수 있지만, 개인 PC나 내부망, 오프라인 환경, 혹은 리소스가 제한된 시스템에서는 부담으로 작용합니다. GGML은 이러한 문제를 해결하기 위해 외부 의존성을 거의 갖지 않는 구조, 그리고 단순한 C 코드 기반 구현을 선택했습니다.
GGML의 핵심 철학은 “작고, 단순하며, 예측 가능한 실행”입니다. 실제로 GGML은 몇 개의 소스 파일만으로 구성되어 있으며, 컴파일된 바이너리 크기 역시 매우 작습니다. 별도의 Python 런타임이나 대형 프레임워크 없이도 모델을 실행할 수 있기 때문에, 환경 이식성이 매우 뛰어납니다. Linux, macOS, Windows는 물론이고 ARM 아키텍처나 Apple Silicon 환경에서도 비교적 쉽게 빌드하고 실행할 수 있습니다.
또 하나의 중요한 특징은 메모리 효율성입니다. GGML은 텐서 표현과 연산에서 불필요한 오버헤드를 제거하고, CPU 캐시 친화적인 메모리 레이아웃을 사용합니다. 특히 GGML이 널리 주목받게 된 이유 중 하나는 강력한 양자화(quantization) 지원입니다. float32 기반 모델을 int8, int5, int4 수준으로 압축해 메모리 사용량을 크게 줄이면서도, 추론 성능을 실용적인 수준으로 유지할 수 있도록 설계되었습니다.
이러한 특성 덕분에 GGML은 학습보다는 추론 중심 라이브러리로 사용됩니다. 이미 학습된 모델을 가능한 한 적은 자원으로 빠르게 실행하는 것이 목적이며, 실제로 llama.cpp, whisper.cpp, GPT4All, LM Studio, Ollama와 같은 여러 프로젝트들이 GGML을 저수준 연산 엔진으로 활용하고 있습니다. 이 경우 GGML은 단순한 모델 포맷이라기보다는, 모델 실행을 담당하는 저수준 런타임에 가깝다고 볼 수 있습니다.
구조적으로 보면 GGML은 내부에 텐서와 연산 그래프를 관리하는 context를 두고, 연산 그래프를 기반으로 계산을 수행합니다. 또한 CPU, CUDA, Metal 등 다양한 백엔드를 지원할 수 있도록 설계되어 있으며, 백엔드별로 메모리 할당과 연산 스케줄링을 분리해 관리합니다. 이러한 구조 덕분에 가볍지만 단순한 수준을 넘는 유연성을 확보할 수 있었습니다.
다만 GGML은 이러한 장점과 함께 한계도 갖고 있습니다. C/C++ 기반 라이브러리 특성상 사용 난이도가 높고, Python 기반 프레임워크에 익숙한 사용자에게는 진입 장벽이 될 수 있습니다. 또한 모델 메타데이터 표현이 제한적이고, 토크나이저나 specia1 token, rope 설정과 같은 부가 정보를 함께 관리하는 데에는 불편함이 존재했습니다. 이러한 한계는 모델이 복잡해질수록 점점 더 문제가 되었습니다.
이러한 배경 속에서 GGML은 점차 GGUF(GGML Unified Format)로 발전하게 됩니다. GGUF는 GGML의 철학을 유지하면서도, 모델 실행에 필요한 메타데이터를 보다 명확하고 확장 가능하게 담기 위해 설계된 포맷입니다. 현재 llama.cpp 생태계에서도 GGML보다는 GGUF 사용이 권장되고 있으며, GGML은 점차 레거시 포맷의 위치로 이동하고 있습니다.
정리하자면, GGML은 “모델을 안전하게 저장한다”는 배포 포맷의 개념보다는, “모델을 가볍고 효율적으로 실행한다”는 목적에 충실한 라이브러리입니다. Python 객체 직렬화나 실행 가능한 코드 로딩과는 거리가 멀기 때문에, 구조적으로 RCE와 같은 취약점과도 무관한 편입니다. 다만 다른 모든 실행 엔진과 마찬가지로, 최종적인 안정성과 보안성은 런타임 구현과 운영 방식에 의해 결정된다는 점은 동일하게 적용됩니다.
GGUF (GGML Unified Format)
GGUF는 GGML을 기반으로 한 개선된 포맷입니다. 이름에서 알 수 있듯 '통합된(Unified)' 형식을 지향하며, 더 많은 메타데이터를 포함하고 확장성을 높였습니다. 이름을 붙일때에도
<BaseName><SizeLabel><FineTune><Version><Encoding><Type><Shard>.gguf 라는 네이밍 규칙을 만들었습니다. 더 많은 메타데이터를 포함할 수 있게 파일구조가 개선되었습니다.
GGUF 는 너무 많은 이야기들이 있는데 따로 다루도록 하겠습니다. 결론은 GGML 은 트랜스포머 모델 서빙 특화 배포 포맷이고, GGUF 는 여기서 관리적인 측면을 고도화한 포맷이라고 생각하면 될 것 같습니다.
GGML /GGUF 의 취약점 발생 가능성
GGML 이나 GGUF 둘다 Python 객체를 포함하지 않고 같은 의미로 pickle 이나 어떤 스크립트를 포함하지 않습니다. 그래서 모델 자체가 코드를 실행시킨다던지의 취약점은 발생하지 않습니다.
프레임워크를 알아보다 보니 정말 너무 많은 프레임워크들이 있더라구요, 그래서 GPT 에게 정리를 좀 해달라 했더니 어디서 사용하고 있는지도 모르는 녀석들까지 가져다 정리를 했네요,
포맷 / 형태
주 사용처
포함 내용
코드 실행 가능성
보안 위험도
장점
단점
권장 사용 여부
safetensors
HF, 내부망, 보안 환경
순수 텐서 가중치
❌ 없음
⭐ 매우 낮음
pickle 미사용, fast mmap, 안전
가중치만 저장
✅ 강력 권장
PyTorch .pt / .pth
연구/개발
Python 객체 + 가중치
🔥 가능
🔥🔥🔥
저장 유연성
pickle 기반 RCE
❌ 배포 금지
HF .bin (pytorch_model.bin)
HF 구버전
pickle 가중치
🔥 가능
🔥🔥🔥
호환성
사실상 .pt
❌
ONNX .onnx
추론/서빙
정적 그래프 + 가중치
❌
⭐ 낮음
프레임워크 독립, 빠름
동적 구조 제한
✅ 추론용
TorchScript .ts / .pt
PyTorch 서빙
IR 그래프 + 가중치
⚠️ 제한적
⚠️ 중간
Python 제거
디버깅 어려움
⚠️ 제한적
TensorFlow SavedModel
TF 서빙
그래프 + 가중치
❌
⭐ 낮음
TF Serving 최적
TF 종속
⚠️
HDF5 .h5
Keras
가중치 + 구조
❌
⭐ 낮음
단순
대규모 모델 한계
⚠️
GGUF / GGML
llama.cpp
양자화 가중치
❌
⭐ 낮음
CPU 친화
학습 불가
✅ 로컬
MLflow model
MLOps
모델 + 메타 + 코드
🔥 가능
🔥🔥
관리 편함
코드 포함
⚠️ 검증 필수
Triton model repo
NVIDIA Triton
모델 + config
❌
⭐ 낮음
고성능 서빙
설정 복잡
✅
Docker image
배포
모델 + 코드 + OS
🔥🔥🔥
🔥🔥🔥
재현성
공격면 큼
⚠️ 내부검증
HF repo (전체)
공유
가중치 + Python
🔥🔥🔥
🔥🔥🔥
편의성
trust_remote_code
❌ 무검증
LoRA / Adapter
파인튜닝
가중치 delta
❌
⭐ 낮음
경량
base 필요
✅
그래서 결론은 모델은 여러 요구사항들을 해결하기 위해서 통합된 프레임워크를 사용했고, 그곳에서 발생하는 취약점은 대체로 pickle 의 직렬화를 사용해서 기대되는 문제점들이였습니다.
그래서 pickle 의 직렬화를 사용하지 않는다면, RCE 같은 치명적인 문제들은 모델 자체에서 생기지 않을 것 같습니다. 다만 모델 런타임 프레임워크에서 발생하는 취약점들은 전혀 다른 영역이니 사용에 참고해야할 것 같습니다.
머신러닝 디자인패턴 4장 모델 학습 디자인패턴 읽던 중 과적합이 사용될 수 있는 사례에 대한 설명을 읽었습니다. 닫힌 해가 없는 경우 즉 데이터가 현실을 100% 반영할 수 있는 경우 계산 overhead 극복을 위해 ML 설계가 도움이 되는데, 이때 과적합이 더 적합하다는 내용을 읽었습니다. 또한 uniform approximation theorem 에서 하나의 hidden layer 와 activation function 이 있는 Network 에 의해 근사될 수 있다는 실험이 많이 증명되었습니다. 이의 연장선으로 조금 뒤 현실세계에서는 모든 입력을 테이블로 만드는 것이 불가능한 경우가 많으니 입력 공간을 샘플링해서 데이터를 만들어내는 몬테카를로 접근방식을 제안했습니다.
그리고 몬테카를로 방법 대신 머신러닝을 활용한다면 PDE 의 데이터 기반 이산화를만들어낼 수 있다고 합니다. 즉, 현실세계의 현상을 모델링하는 PDE 를 직접만들지 말고 머신러닝을 활용해서 확보된 데이터필드를 어떻게 섞어야하는지를 학습시키는 것 입니다. 함수없이 함수에 근사시키려는 노력입니다.
그리고 본 포스팅에서 리뷰할 논문이 바로 이에 대한 효과를 잘 보여준 Learning data driven discretization for partial differential equations 입니다.
요약
PDE 의 수치적 솔루션은 다차원의 시공간적 피처들을 잘 해결하지 못합니다. ( 차원의 저주 ) 이걸 해결하려면 너무 많은 양의 계산이 필요하기 때문인데요. 기존의 유일한 방법은 좀 제대로하지 못할지라도 근사시키려고 노력하는 것 입니다. 근데 물론 그것도 어마어마하게 어렵습니다. 그래서 해당 논문에서는 현상에 PDE 를 근사시키는 것이 아니라 data driven 방정식을 제안합니다. PDE를 일반적으로 알려진 방정식에 기반해서 neural network 를 사용해 차원의 저주 문제를 해결할 방법입니다.
다시 정리하자면 기존 PDE 문제를 해결할 때 접근은 잘 정의된 PDE를 얼마나 정확하게 근사시킬 것인지 였지만, 이제는 PDE를 정확하게 근사하지 않고 이산화된 연산자를 데이터에 기반해 학습시키자는 관점입니다.
일반적으로 대부분의 물리현상은 PDE 로 표현할 수 있고 시간에 따라서 변하는 연속적인 물리량은 아래와 같이 나타낼 수 있습니다. 문제는 이걸 컴퓨터로 풀어내는 방법인데요,
컴퓨터는 연속적인 데이터를 직접 다룰 수 없기 때문에 우리가 인지할 수 있는 grid 위에 이산적으로 표시하게 됩니다. 그리고 최대한 연속적으로 다루려고 노력하지요. 이때 유한차분 (FD) 을 통해서 시간에 대한 ODE Form 으로 바뀌게 됩니다.
여기서 F 는 이제 이것들을 gird 주변의 값들로 근사해야 하는데,
여기서 a(i)^n 을 신경망으로 학습해서 국소적 구조에 따라 현실에 다가가도록 설계하는 것 입니다. 고해상도 시뮬레이션 데이터로 학습 데이터를 만들고 해당 식에 등장하는 미분항들의 이산근사식( 여기서는 sigma alpha ^ n v(i) ) 을 학습합니다. 이 과정이 계산비용 측면에서의 트레이드 오프를 만드는데 이건 전체 필드가 아닌 작은 부분에서 고해상도 시뮬레이션 데이터를 추출해 완화할 수 있습니다. 이렇게 하면 훨씬 큰 시스템에[서도 낮은 공간에서 얻은 데이터로 계산할 수 있습니다.
→ 작은 지역에서 solution manifold 위의 실제 현상을 잘 근사하면 , 그 국소적 이산화 규칙(ML 모델)이 더 큰 시스템에서도 재사용 가능하다고 하는 것 입니다. 그러니까 중요한 것은 완벽한 적합이 아니라 국소 영역에서 실제 물리계의 역학 상태를 잘 포착(근사)하는 것입니다.
실제로 신경망을 활용해 실제 현상에 기여하는 비교를 해보면 방정식으로 근사하는 것보다 성능이 더 좋다고 주장합니다.
기여도
이 논문의 가장 큰 기여는 PDE 해법 자체가 아니라, PDE 이산화를 학습의 대상으로 재정의했다는 점입니다. 기존 수치해석은 미분 연산자를 보편적으로 근사하려고 시도했는데요, 본 연구는 해가 실제로 존재하는 solution manifold 위에서만 유효한 국소 이산화 규칙을 데이터로부터 학습합니다.
구체적으로는 다음과 같은 기여가 있습니다.
첫째, equation-specific discretization이라는 개념을 명확히 제시합니다. 유한차분 계수는 보편적이어야 한다는 기존 관점에서 벗어나, 방정식과 국소 상태에 따라 달라지는 이산화 계수를 허용함으로써 under-resolved 조건에서도 높은 정확도를 달성합니다.
둘째, solution manifold 기반 학습 관점을 제시합니다. 신경망은 전체 함수 공간을 근사하는 것이 아니라, 물리적으로 가능한 해가 놓이는 저차원 다양체(manifold)만을 파라미터화합니다. 이로 인해 격자 해상도를 낮추더라도 실제 물리적 동역학을 유지할 수 있음을 보입니다.
실험결과
본 논문에서는 데이터 기반 이산화가 실제 PDE 문제에서 기존 수치해석보다 얼마나 뛰어난지 보이기 위해 여러 대표적 비선형 PDE를 대상으로 실험을 수행했습니다. 그중 가장 중요한 것은 1차원 Burgers’ equation인데요, 이 방정식은 간단하지만 충격파(shock) 형성과 같은 복잡한 비선형 현상을 포함해 수치적 근사가 어렵다는 점에서 이상적인 테스트베드입니다.
burger’s equation 은 아래와 같이 쓰입니다.
burger’s equation 은 해상도를 많이 낮춘 경우에도 발산하지 않고 오차가 줄어들었으며 충격파의 위치화 형태를 안정적으로 적분했습니다. 신경망이 충격파와 같은 비선형적이고 예측하기 힘들보이는 비선형PDE에서도 그 구조를 잘 반영했기 때문입니다.
이 실험으로 추가적으로 학습 도메인보다 훨씬 큰 도메인에서도 잘 작동함을 증명했습니다. 논문을 읽으며 초반에 국소적 영역의 실제 데이터로만 학습시켰는데, 과연 모든 영역에서 잘 작동할까? 걱정했지만, trainig domain 보다 10배 더 큰 공간에서도 burger’s equation 을 풀어보았음에도 잘 작동하여 일반화 했음을 보여줍니다.
결론은 실험결과를 통해 데이터 기반 이산화가 전통적 수치해법보다 정교하고 쉬우며 안정적이라는 것을 보여줍니다.
향후 연구 방향
연구에서는 두가지 챌린지가 남아있다고 합니다.
첫번째로, 속도입니다. FD 를 구현할 때 많은 convolution 연산을 사용합니다. 저자들은 이것보다 다른 머신러닝 접근법이 훨씬 더 빠를 수 있다고 생각하고 있고, pre-trained linear filter 가 수십배 이상의 성능 향상을 보인바가 있습니다.
두번째는 고차원 문제와 higher dimensional problem 입니다. 2,3차원에서는 dimension 이 제곱, 세제곱으로 커지니 연산 overhead 를 더욱 줄여 이득을 기대할 수 있습니다.
batch normalizaion 은 2015년에 제시된 ICS(Internal Covariate Shift) 문제를 줄일 수 있는 아이디어입니다. covariate shift 는 학습 때 활용한 데이터가 실제 추론에 사용되는 데이터간의 분포가 다르면 추론 성능에 악영향을 미칠 수 있다라는 주장인데 이게 신경망 내부에서도 발생할 것이다 라는 주장을 하며 생긴용어가 Internal Covariate Shift 라고 합니다. 아래 사진을 보면 직관적으로 이해가 될 것 같습니다. 신경망을 통과하면서 데이터의 분포가 달라지는 현상이 발생하는데
통과하는 레이어 수가 많아질수록 그 정도가 심해지기 때문에 당연히 추론이나 학습 성능에 문제가 생길 확률이 큽니다. Batch Normalizaion 은 기존의 정규화 과정에서 학습데이터마다 분포가 다른것을 배치별로 평균과 분산을 활용해 정규화하는 것 입니다.
나동빈님의 영상을 참고하여 알게 된 batch normalizaion가 현실에서는 하이퍼파라미터 의존도를 줄였으며, 학습속도를 향상시키고, 모델이 일반적으로 즉, 학습데이터에만 태스크를 잘 처리하도록 하는것이 아닌 실제 현상을 잘 반영시키게 된 효과가 있었다고 합니다.
그런데 논문에서는 ics 를 감소시킨다고 주장하였으나 실제로 증명하지는 못했다고 합니다. 그래서 그것을 증명하기 위한 How Does Batch Normalization Help Optimization? 라는 논문이 나왔습니다.
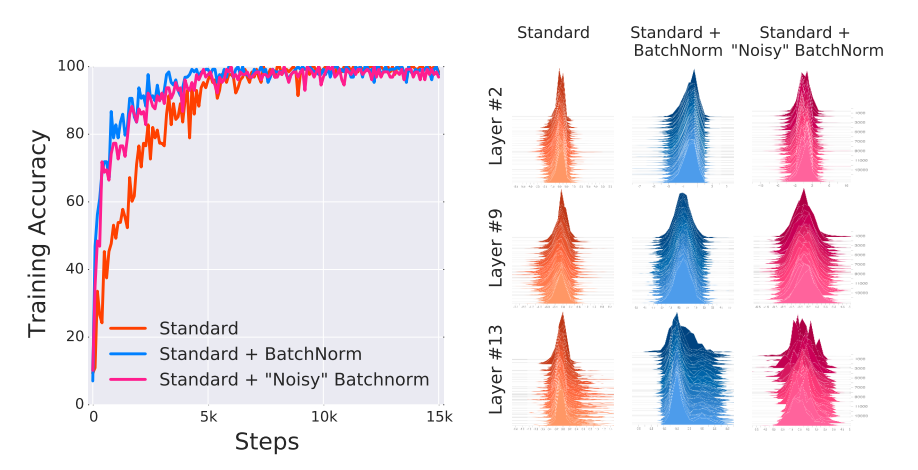
우선 일반적으로 Batch Norm 을 적용시킨 네트워크가 Accuracy 가 가파른 폭으로 올라갔다는 것을 보여줍니다.
우측의 히스토그램을 보면 각 레이어의 분포를 나타내고 있는데요 가장우측의 Standard + Noisy BatchNorm 에서 Layer3 부터 분포가 갑작스럽게 변하여 ICS가 발생하고 있음을 볼 수 있습니다. ICS가 발생하고 있음에도 불구하고 왼쪽 그래프를 보면 학습성능이 우수함을 볼 수 있습니다.
즉 임의로 Batch Norm Layer 이후 바로 Noise 를 넣어 covariate shift 를 발생시켰을 때에도 BatchNorm 이 포함된 네트워크는 일반적인 네트워크보다 성능이 우수함을 보였습니다. 그래서 실험적으로 Batch Norm 이 ICS 문제를 해소할 수 있다는 이전 논문의 반박을 하였고, 심지어 ICS가 크게 발생함에도 불구하고 Batch Norm 이 있으면 성능이 좋아진다는 것을 보여준 사례가 되었습니다.
해당논문에서 ICS를 파라미터의 기울기 계산하여 ICS를 계산하는 방법을 제안했는데, 포스팅의 목적보다 너무 벗어나는것 같아 다루지 않겠습니다. 궁금하신분께서는 논문을 참고하시면 될 것 같습니다.
그렇다면 ICS 를 해소하지 못했음에도 불구하고 성능이 좋은 이유는 뭘까요? 논문에서는 Batch Norm 의 Smoothing 효과 때문이라고 설명합니다.
Loss Landscape 가 훨씬 더 예상 가능한 범위로 형성되면서 학습효과가 증대된다고 말하고 있습니다.
Batch Normalization Layer
미니배치의 평균값과 분산을 구해서 normalizaion 을 수행할 수 있습니다. 그리고 감마와 베타를 활용해 실제 output 을 내는데요, 여기서 감마와 베타가 실제 학습에 활용되는 파라미터입니다. 학습중에는 loss 를 최소화 하는 방향으로 감마와 베타를 찾아갈 것 입니다.
정규화에서 학습 파라미터를 사용하는 이유는 활성화 함수의 특징에 있습니다. sigmoid를 예시로 들면 어떤 구간에서는 매우 선형적으로 작동하기 때문에 표준정규분포로 정규화한 0과 1사이의 값에서 선형적으로 작동하게 됩니다. 그래서 감마와 베타를 활용해 non-linearity 를 지켜주고, 해당 정규화 레이어의 output 도 적절하게 내보낼 수 있게됩니다. 결론은 레이어의 입력을 정규화할 때는 linearity 를 주의해서 정규화 해야한다는 점 입니다.
Batch Normalization Layer 연산구분
batch normalization Layer 는 학습할때와 추론할 때 네트워크에서의 역할이 달라집니다. 학습할때 감마와 베타 파라미터를 학습시켜야 하지만 추론때에는 필요없습니다. 따라 해당 파라미터들을 고정하여 학습된 파라미터에 의한 값이 나와야합니다.
step 7 에서부터는 BN 이 training 모드로 네트워크에 있었던 것을 inference 모드로 바꿉니다. ( 파라미터 고정을 통해서 )
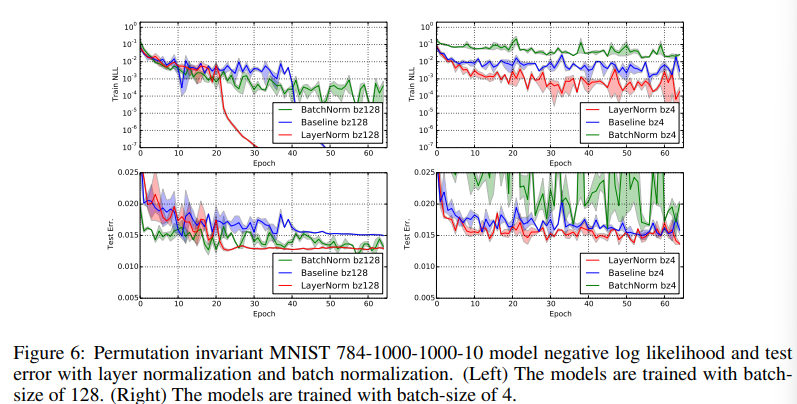
Layer Normalization 은 Batch Norm 이 RNN 에 적용하기 어려운 문제점을 해소하기 위해 제시된 방법입니다. RNN은 시간단위로 계산을 합니다. 따라서 미니배치의 각 피쳐마다 통계를 이용해 정규화하는 BN 의 경우에는 해당 스트림의 맥락을 반영하지 못합니다.
가장 큰 문제는 RNN 이나 NLP, 혹은 음성데이터의 경우는 배치마다 길이가 다릅니다.
샘플 1: "나는 밥을 먹었다" (길이 4)
샘플 2: "오늘" (길이 1)
샘플 3: "어제 비가 와서 우산을 썼다" (길이 6)
이것을 BN 을 활용한 Layer output 을 사용한다면 샘플2 의 2,3 샘플1의 3,4 가 0이 됩니다. 그렇기 때문에 데이터의 의미를 충분히 반영하지 못하는 문제가 발생합니다. 이 문제는 시계열 데이터에도 그대로 적용됩니다. 이미지나 성적통계(국어는 국어끼리, 수학은 수학끼리) 와 같은 데이터가 아니라 피쳐하나가 다른 피쳐나 데이터에도 영향을 주는경우는 Batch 사이즈에 영향을 받지 않고 데이터의 의미를 잘 반영할 수 있는 LN 이 성능이 좋다고 주장합니다.
BN 과의 차이점
Batch Normalization은 미니배치 단위로 평균과 분산을 계산하여 정규화를 수행합니다. 반면 **Layer Normalization(LN)**은 이름 그대로 레이어 단위, 정확히는 하나의 샘플 내부 feature들에 대해서만 정규화를 수행합니다. 즉, 정규화의 기준이 완전히 다릅니다.
Transformer 구조에서 Layer Normalization 이 Batch Normalization 보다 적합한 이유
1. 시퀀스 길이 가변성과 Masking 문제
Transformer의 Self-Attention은 가변 길이 시퀀스를 처리해야 합니다. 입력형태는 각 문장마다 길이가 다르다는 점입니다. 이를 해결하기 위해 짧은 문장에는 padding을 추가하 attention mask를 사용해야 합니다.
Batch Normalization을 이러한 구조에 적용하면 심각한 문제가 발생합니다. BN은 배치와 시퀀스 차원 전체에 걸쳐 평균과 분산을 계산하는데 위에서 봤던 것 처럼 의미 없는 padding 토큰의 0 벡터가 통계에 포함됩니다. 결과적으로 문장 길이에 따라 정규화 통계가 왜곡되고, 같은 내용의 문장이라도 padding의 양에 따라 다르게 정규화될 수 있습니다.
반면 Layer Normalization은 각 토큰의 feature 차원에 대해서만 정규화를 수행합니다. 즉, 하나의 토큰 내부에서만 평균과 분산을 계산하기 때문에 padding 토큰이나 시퀀스 길이가 정규화 통계에 전혀 영향을 미치지 않습니다. 각 토큰은 독립적으로 정규화되므로 데이터의 의미가 충실히 반영되고 배치나 시퀀스 구조와 무관하게 일관된 정규화가 가능합니다.
2. Autoregressive Decoding과 배치 크기 불일치
Transformer Decoder는 추론 시 미래의 정보를 참조하지 못하도록 autoregressive 방식으로 동작합니다. 즉, 이전에 생성한 토큰을 바탕으로 다음 토큰을 하나씩 순차적으로 생성합니다. 이 과정에서 대부분의 경우 배치 크기가 1이 됩니다. 이는 Layer Normalization 논문에서 보여준것처럼 Batch Normalization에 치명적인 문제를 야기합니다.
Layer Normalization은 배치 크기와 무관하게 안정적으로 동작합니다. 배치 크기가 1이든 32든 정규화 결과는 일관되며, 학습 시 관찰한 성능이 추론 시에도 그대로 유지됩니다. 이는 Transformer Decoder의 생성 품질에 결정적으로 중요한 특성입니다.
3. Residual Connection과의 구조적 불일치
Transformer의 각 블록은 residual connection을 사용합니다: y = x + Sublayer(LN(x)). 이 구조가 중요한 이유는 gradient의 흐름 때문입니다. 역전파 시 ∂y/∂x = 1 + ∂Sublayer/∂x 가 되어, gradient가 항상 직접 흐를 수 있는 경로(identity mapping)가 보장됩니다. 이는 깊은 네트워크에서 gradient vanishing 문제를 해결하는 핵심 메커니즘입니다.
만약 Batch Normalization을 residual path에 사용하면, BN의 출력이 배치 통계에 의존하기 때문에 residual path에 batch-dependent noise가 주입됩니다. 이는 gradient flow를 불안정하게 만들고, 특히 깊은 Transformer에서는 gradient 폭발이나 소실을 일으킬 수 있습니다. 실제로 Post-LN Transformer(residual 후에 LN을 적용)는 레이어가 깊어질수록 학습이 불안정해지는 것으로 알려져 있으며, Pre-LN Transformer(residual 전에 LN을 적용)가 더 안정적인 학습을 보입니다. BN은 이러한 residual connection의 특성과 근본적으로 충돌합니다.
Layer Normalization은 각 샘플을 독립적으로 정규화하기 때문에 배치에 의존하지 않습니다. 따라서 residual path의 gradient flow를 방해하지 않으며, 수십 개의 레이어로 이루어진 깊은 Transformer에서도 안정적인 학습이 가능합니다. 이러한 구조적 조화가 Transformer가 Layer Normalization을 사용하는 또 다른 중요한 이유입니다.
대고객 챗봇 개발 당시 hallucination 에 관한 기준이 엄격해 모르는 답변은 모른다고 답변하고 상담원 연결로 돌리는 로직으로 설계되어 있었습니다.
때문에 고객이 chain 구조에서 조금만 예상에 어긋나는 행동을 하면 답변을 회피(모르겠다 답변 후 상담원 연결) 해 상담 만족도가 떨어지는 문제가 발생했는데요, 그래서 질문에 유연하게 대응하기 위해 체인구조에서 ReAct agent 로 마이그레이션 하기로 했습니다.
체인에 도달할 때에는 정해진 DTO 를 지켜야 했는데 체인이 있는 Tool 까지 도달할 때에는 이미 LLM 에 의해 DTO 가 뭉개져 Tool 에 인자를 전달하지 못하는 문제가 발생했습니다. 이때 프롬프트로만 출력을 제어했었는데, 답변을 잘하는 것 처럼 보였지만 Langsmith 로 agent tool calling을 추적한 결과 내부적으로는 일부 데이터들을 누락되고 calling 을 반복 하는 문제가 발생했습니다. 아마 강력한 프롬프트를 쓰면 좀 나아졌겠지만 결과적으로 이 문제는 응답시간 지연과, 토큰 비용 증가로 이어졌습니다. 하지만 고객반응과 실제 비지니스 문제해결에는 문제가 없었기 때문에 우선순위에 밀려 기술부채로 남게되었습니다.
지금 회사에 오게 되면서 structured output 에 관한 개념을 접하게 되고 신뢰가능한지, 실제 대고객 업무에서 사용할 만큼 신뢰도 있는지 확인해보려고 합니다.
Structured Output 의 작동원리
먼저 structured output 은 LLM 의 output 을 Json 이나 Pydantic 혹은 dataclass 같은 형태로 받을 수 있는 기능입니다. 또한 에러처리가 가능한데, 모델이 범위를 어긋나게 응답하거나 자료형을 틀리게 매칭한다면 validation error 를 만들 수 있어 에러메시지 유도가 가능합니다.
이것을 잘 활용하면 특정 경우에만 (format 이 맞지 않는 경우, 필드에 값이 잘못 들어가는 경우) Error를 발생시킬 수 있습니다. 일반적으로는 재시도를 하게되고 재시도 하는 경우 대부분 잘 매칭이 됩니다. 가장 치명적인 것은 structure 에 맞게 데이터를 넣기는 하지만, 그 값이 실제로 맞는지는 보장하지 않는 다는 것을 고려해야합니다.
작동 순서
모델과 스키마를 입력받는다.
langchain 내부에서 전략을 선택함
toolcalling strategy : 모델이 structured output 지원하지 않는 경우
class ReviewSummary(BaseModel):
title: str = Field(..., description="리뷰 제목")
sentiment: str = Field(..., description="긍정/부정/중립 중 하나")
score: float = Field(..., description="0~1 사이의 감정 점수")
from langchain_openai import ChatOpenAI
# OpenAI API 또는 vLLM OpenAI 서버 URL로 자동 연결됨
model = ChatOpenAI(
model="gpt-4o-mini", # 아무 모델 가능
temperature=0
)
structured_model = model.with_structured_output(ReviewSummary)
result = structured_model.invoke(user_input)
print(result)
print(type(result))
------------
title='영화 리뷰 요약'
sentiment='부정'
score=0.15
<class '__main__.ReviewSummary'>
------------
structured output 지원하는 일부 모델들은 아래처럼 벤더사가 지원하는 스키마에 맞게 변환하는 도구만을 bind 한 채로 끝나게 됩니다.
class ChatAnthropic(BaseChatModel):
#----------중략----------
def with_structured_output():
#----------중략----------
if method == "function_calling":
formatted_tool = **convert_to_anthropic_tool(schema)**
tool_name = formatted_tool["name"]
if self.thinking is not None and self.thinking.get("type") == "enabled":
llm = self._get_llm_for_structured_output_when_thinking_is_enabled(
schema,
formatted_tool,
)
else:
llm = self.bind_tools(
[schema],
tool_choice=tool_name,
ls_structured_output_format={
"kwargs": {"method": "function_calling"},
"schema": formatted_tool,
},
)
@dataclass(init=False)
class ProviderStrategy(Generic[SchemaT]):
"""Use the model provider's native structured output method."""
schema: type[SchemaT]
"""Schema for native mode."""
schema_spec: _SchemaSpec[SchemaT]
"""Schema spec for native mode."""
def __init__(
self,
schema: type[SchemaT],
) -> None:
"""Initialize ProviderStrategy with schema."""
self.schema = schema
self.schema_spec = _SchemaSpec(schema)
그리고 Provider 에 없는 모델은 ToolStrategy 를 사용하게 되는데 vllm 같은 로컬 서빙 프레임워크에서 작동시키는 모델들이 대체로 그러합니다.
@dataclass(init=False)
class ToolStrategy(Generic[SchemaT]):
"""Use a tool calling strategy for model responses."""
schema: type[SchemaT]
"""Schema for the tool calls."""
schema_specs: list[_SchemaSpec[SchemaT]]
"""Schema specs for the tool calls."""
tool_message_content: str | None
"""The content of the tool message to be returned when the model calls
an artificial structured output tool."""
handle_errors: (
bool | str | type[Exception] | tuple[type[Exception], ...] | Callable[[Exception], str]
)
ToolStrategy 는 bind 메서드를 사용하여 러너블 객체에 접근하고 그 지점에 툴콜링을 하게 됩니다.
사람이 개입하여 벤더사의 툴을 호출할 수 있지만 전략선택의 결정적으로 큰 차이는 결국 with_structured_output 함수를 호출할 때 기본으로 선택되는 method 가 다르다는 것입니다.
모델이 structured output 지원하지 않는 경우
def with_structured_output(
self,
schema: dict | type,
*,
method: Literal["function_calling", "json_mode", "json_schema"] = "json_schema",
include_raw: bool = False,
**kwargs: Any,
) -> Runnable[LanguageModelInput, dict | BaseModel]:
r"""Model wrapper that returns outputs formatted to match the
structured output 지원하는 경우
def with_structured_output(
self,
schema: dict | type,
*,
include_raw: bool = False,
method: Literal["function_calling", "json_schema"] = "function_calling",
**kwargs: Any,
) -> Runnable[LanguageModelInput, dict | BaseModel]:
"""Model wrapper that returns outputs formatted to match the given schema.
structured output 을 지원하는 경우에는 method 가 function_calling 으로 api 제공 벤더사의 function calling 형태로 처리하고
if method == "function_calling":
formatted_tool = convert_to_anthropic_tool(schema)
tool_name = formatted_tool["name"]
if self.thinking is not None and self.thinking.get("type") == "enabled":
llm = self._get_llm_for_structured_output_when_thinking_is_enabled(
schema,
formatted_tool,
)
else:
llm = self.bind_tools(
[schema],
tool_choice=tool_name,
ls_structured_output_format={
"kwargs": {"method": "function_calling"},
"schema": formatted_tool,
},
)
bind_tools 메서드를 사용하고 있습니다.
반대의 경우에는 json_schema 가 기본 선택되어 bind 메서드를 사용해서 tool calling 형태가 아니라 runnable sequence 에 새로운 객체를 만들어 호출 옵션을 재정의는 것입니다.
elif method == "json_schema":
if schema is None:
msg = (
"schema must be specified when method is not 'json_mode'. "
"Received None."
)
raise ValueError(msg)
if is_pydantic_schema:
schema = cast("TypeBaseModel", schema)
if issubclass(schema, BaseModelV1):
response_format = schema.schema()
else:
response_format = schema.model_json_schema()
llm = self.bind(
format=response_format,
ls_structured_output_format={
"kwargs": {"method": method},
"schema": schema,
},
)
output_parser = PydanticOutputParser(pydantic_object=schema) # type: ignore[arg-type]
##bind example
"""
Example:
```python
from langchain_ollama import ChatOllama
from langchain_core.output_parsers import StrOutputParser
model = ChatOllama(model="llama3.1")
# Without bind
chain = model | StrOutputParser()
chain.invoke("Repeat quoted words exactly: 'One two three four five.'")
# Output is 'One two three four five.'
# With bind
chain = model.bind(stop=["three"]) | StrOutputParser()
chain.invoke("Repeat quoted words exactly: 'One two three four five.'")
# Output is 'One two'
"""
자체적으로 response_format 을 세팅하고 있는 것을 볼 수 있습니다. 이렇게 스키마를 입력받고 전략을 선택하는 로직을 거치게 됩니다.
langchain 은 schema_spec 을 이용해서 fake tool schema 를 생성하고 이 fake tool 이름이 structured output 같은 형태로 모델에게 전달됩니다. 그럼 모델은 아래와 같은 형태로 응답합니다.이제 json 을 파싱해서 pydantic 이나 dataclass 검증을 하고 실패하면 Validation Error 을 뱉어내고 다시 모델에게 요청을 하게 됩니다.
이 error 이후 다시 모델에게 요청하는 과정에서 만약 모든 컨텍스트를 포함한 체인이나 노드라면 정말 많은 토큰이 낭비되고, 응답시간이 지연되게 됩니다.모델이 native 하게 structured output 을 지원하지 않는 경우 Toolcalling strategy 를 선택하게 됩니다.
ProviderStrategy
@dataclass(init=False)
class ProviderStrategy(Generic[SchemaT]):
"""Use the model provider's native structured output method."""
schema: type[SchemaT]
"""Schema for native mode."""
schema_spec: _SchemaSpec[SchemaT]
"""Schema spec for native mode."""
langchain 은 스키마만 그대로 모델에게 전달하고 응답받아서 파싱만 수행합니다. openAI 와 anthropic gemini 의 응답은 안정적으로 다시 모델에게 요청하는 경우가 적습니다. 모델이 자체적으로 structured output 을 지원하는 경우입니다. 이때 langchain 은 각 벤더사에 맞는 형태로 변환/파싱을 수행합니다.
Structured Output 테스트
openai 의 structured otutput은 아래의 장점을 갖고 있는데, 특히 세번째 부분이 인상적이었습니다. 이전 챗봇 개발당시 레거시는 이 기능을 몰랐던것인지 프롬프트로 출력을 강제하고 있었는데, structured output 을 사용하면format 을 지키기 위해서 강력한 프롬프트를 하지 않아도 되기 때문입니다.
structured output 이 언제 지원되도록 포함되었는지 확인해보니 Toolcalling strategy 는 2023년 중후반쯤 그리고 ProviderStrategy는 2024년 8월 6일 gpt-4o 모델을 시작으로 openai 가 가장먼저 지원했습니다. 그 다음 anthropic 과 gemini 가 차례로 지원하기 시작했습니다.
langchain 스테이블버전이 2024년 1월에 배포되고, 그때부터 챗봇 레거시가 개발되기 시작했으니 최초 시스템 개발 이후 신기술 추적을 1년 6개월 가까이 하지 않았다는 것을 알 수 있었습니다.
그럼 실제로 프롬프트로 출력을 강제하는 것과 structured output 으로 output 형태를 파싱하는 것이 얼마나 다른지 확인해보겠습니다.
위 규칙과 예제를 모두 참고하여, 지금부터 어떤 입력이 들어오더라도 Pydantic UserInfo 스키마에 완전히 맞는 JSON만 출력하라.
사고 과정은 내부적으로만 사용하고 절대 외부로 노출하지 않는다."""
Structured Output Pydantic 파라미터 전달 테스트
structured output 은 공식문서에서도 “structured output 은 실수할 수 있다” , “최대한 스키마에 대한 정보를 잘 작성해라” 라고 말하고 있습니다. 그래서 따라서 LLM 이 분류하거나, 어떤 포맷에 입력을 강제해야한다면 Pydantic 사용하기를 권장합니다.
간단한 프롬프트의 경우 둘다 잘 뱉어내는 것을 볼 수 있습니다.
그럼 실무에서 발생하는 시나리오를 생각해보고 테스트 해보겠습니다. LLM 이 섭취하게 될 데이터는 생각보다 복잡할 수 있습니다. 특히 여러개 DTO 가 섞여있는 경우 DTO 가 기하급수적으로 커지게 되는데요 3개의 DTO를 예시로 하여 json 타입이 아닌 자연어로 데이터를 주었을 때 잘 파싱하는지 확인해보겠습니다.
class Gender(str, Enum):
male = "male"
female = "female"
other = "other"
class Address(BaseModel):
street: str = Field(description="Street name and number")
city: str = Field(description="City name")
state: str = Field(description="State/Province")
postal_code: str = Field(description="Postal/ZIP code")
country: str = Field(description="Country name")
class UserProfile(BaseModel):
name: str = Field(description="The user's full name")
age: int = Field(description="The user's age")
gender: Gender = Field(description="The user's gender")
email: str = Field(description="The user's email address")
phone_number: str = Field(description="The user's primary phone number")
addresses: List[Address] = Field(description="List of user's addresses")
date_of_birth: date = Field(description="The user's birth date")
interests: List[str] = Field(default_factory=list, description="List of user's interests")
is_active: bool = Field(default=True, description="Whether the user is active")
bio: Optional[str] = Field(default=None, description="Short biography of the user")
friends_ids: Optional[List[int]] = Field(default_factory=list, description="List of friend's user IDs")
account_created: date = Field(description="Date when the user account was created")
Input은 아래와 같이 했다.
박준호라는 사용자의 정보를 JSON으로 만들어주세요.
나이는 24세, 남성이며, 이메일은 park.junho@example.com,
전화번호는 010-1111-2222입니다.
주소는 부산 해운대구 마린시티 5번지와 대구 수성구 범어로 88번지입니다.
생일은 2000년 12월 1일, 관심사는 게임, 코딩, 축구입니다.
사용자는 비활성 상태(False)이며, 자기소개는 게임 개발자를 꿈꾸고 있는 대학생입니다.
친구 ID는 301, 302, 계정 생성일은 2021년 6월 20일입니다.
복잡한 구조적 데이터를 프롬프트로 형태를 강제한 것도 대체로 잘 파싱하는 것을 볼 수 있습니다. 하지만 결과물을 보면 postal code에 포함되어 있지 않은 데이터가 들어있습니다.
그렇다면 structured output 을 사용한 쿼리는 어떨까요?
찬가지로 잘 파싱합니다. DTO가 복잡해지더라도 좋은 모델인 경우에는 거의 다 파싱을 해내는 것을 볼 수 있었습니다. 하지만 한가지 차이점이 발생했는데요 with structured output 메서드는 postal_code 가 빈칸인 것을 볼 수 있습니다. 하지만 prompt 로 강제한 경우에는 실제 데이터에 postal code 가 없음에도 불구하고 dummy 데이터가 들어가있는 것을 볼 수 있습니다.
Structured Outpu는 신뢰할 수 있을까
지금까지 내용으로 structured output 을 사용할 때 조금 더 잘 파싱이 되는 것을 볼 수 있었는데요, 훨신 간결하고 성능이 좋으니 따라서 프롬프트로 강제하는 것보다 structured output 기능을 사용하는것이 훨씬 더 유리할 것 같습니다.
실험에 사용한 gpt-4o 모델보다 괜찮은 로컬 모델들이 많은데요 30B 정도 되는 모델들을 사용한다면 로컬에서 돌리는 모델들도 잘 작동할 것이라 예상합니다. 그래서 성능측면에서 어떤 전략이 더 우월하다는 것은 큰 의미가 없어보입니다.
하지만 그럼에도 불구하고 Toolcalling Strategy 의 경우는 retry 가 자주 발생할 수 있기 때문에 structured output 지원되는 api 를 사용할 수 있는 환경이라면 ProviderStrategy 를 사용할 수 있는 방법으로 시도해야 한다고 생각합니다.
이제 출력 구조를 프롬프트로 강제하는 것보다 structured output 을 사용하는 것이 좋다는 것은 알게 되었습니다. 그럼 결정적으로 structured output 을 신뢰할 수 있을까? 에 대한 답을 구해야하는데, 최근 아래의 글을 읽게 되었습니다.
시니어 개발자들이 주니어 개발자들보다 AI Agent 를 개발하는게 느리다는 주제로 시작한 글인데 그 이유를 생각하면 사뭇 철학적으로 받아들여야 할 부분이 있습니다.
이유는 전통적인 소프트웨어 엔지니어링(엄격한 제어, 결정론적) 그러니까 맞으면 맞는거고 틀리면 틀린거지, 틀리면 고쳐야지 라는 전통적인 엔지니어링의 철학과 습관이 AI 에이전트 개발에 방해가 되고 있다는 겁니다. 글의 저자인 Phillipp Schmid 는 시니어일수록 LLM 의 불확실성을 코드로 제거하려고 하는 경향이 있어 주니어보다 느려진다는 것입니다.
텍스트 데이터의 맥락을 구조화 된 것으로 강제하면 LLM이 잘하는것을 오히려 더 못하게 하면서 성능이 떨어지고 성능이 떨어지는 이유를 코드로 제거하려 하니 수렁에 빠지게 된다의 의미인 것 같습니다.
import sys
n,m = map(int,input().split(' '))
pocketmon_list = dict()
rev_poecketmon_list = dict()
cnt=1
for i in range(0,n):
name = sys.stdin.readline().strip()
pocketmon_list[str(cnt)] = name
rev_poecketmon_list[name] = str(cnt)
cnt+=1
for i in range(0,m):
tmp_input = sys.stdin.readline().strip()
if tmp_input.isdigit():
print(pocketmon_list[tmp_input])
else:
print(rev_poecketmon_list[tmp_input])
위 글을 참고하기 바란다. 결론은 value로 key 를 직접 찾는 것은 for 문을 사용한 완전탐색밖에 없다.
2. 왜 input() 이 sys.stdin.readline().stirp() 보다 느릴까?
input() 함수는 Python 에서 기본적으로 제공하는 사용자 입력 함수인데 다음과 같은 특징을 갖고 있다.
1. 입력 된 값을 '문자열로 반환' 하고 '자동으로 개행 문자 제거' 를 한다.
2. 프롬프트 메시지를 인자로 받을 수 있다.
여기서 이 문자열로 변환하여 반환하고 자동으로 개행 문자를 제거하는게 물리적으로 시간이 대단히 오래걸린다.
그에 반해 readline() 함수는 개행 문자를 포함하여 문자열을 반환한다. 그렇기 때문에 그 시간 차이가 발생하는데 readline 함수에서는 strip() 을 사용하여 개행문자를 지울 수 있다.
두 함수의 시간차이를 보여주는 함수이다.
import sys
import time
# sys.stdin.readline() 사용
start = time.time()
for _ in range(100000):
line = sys.stdin.readline().strip()
end = time.time()
print(f'sys.stdin.readline() 사용 시간: {end - start}초')
# input() 사용
start = time.time()
for _ in range(100000):
line = input()
end = time.time()
print(f'input() 사용 시간: {end - start}초')
100000줄의 입력을 처리하는 데 걸리는 시간:
input() 함수: 12.3456초
sys.stdin.readline() 함수: 0.4567초
결과값은 어마어마하게 차이가 난다. 따라서 python 에서 시간초과문제를 겪을 때 input 을 sys.stdin.readline().strip() 으로 변경해보자.